右键网页检查 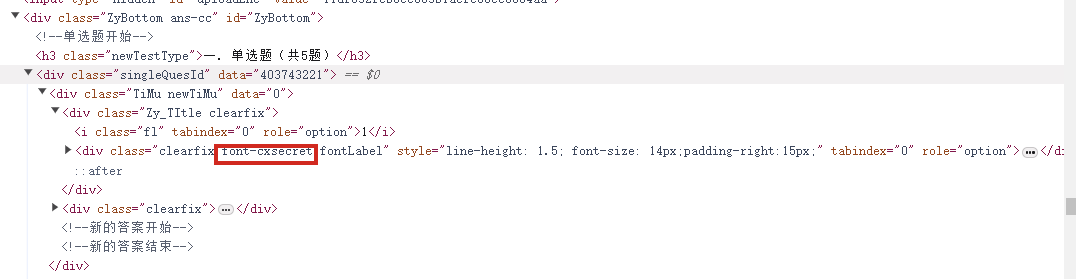 搜索页面和这个相关的从而定位到引入文件  查找,一眼Base64编码的字体文件,通过这个编码数据解码获得原字体文件 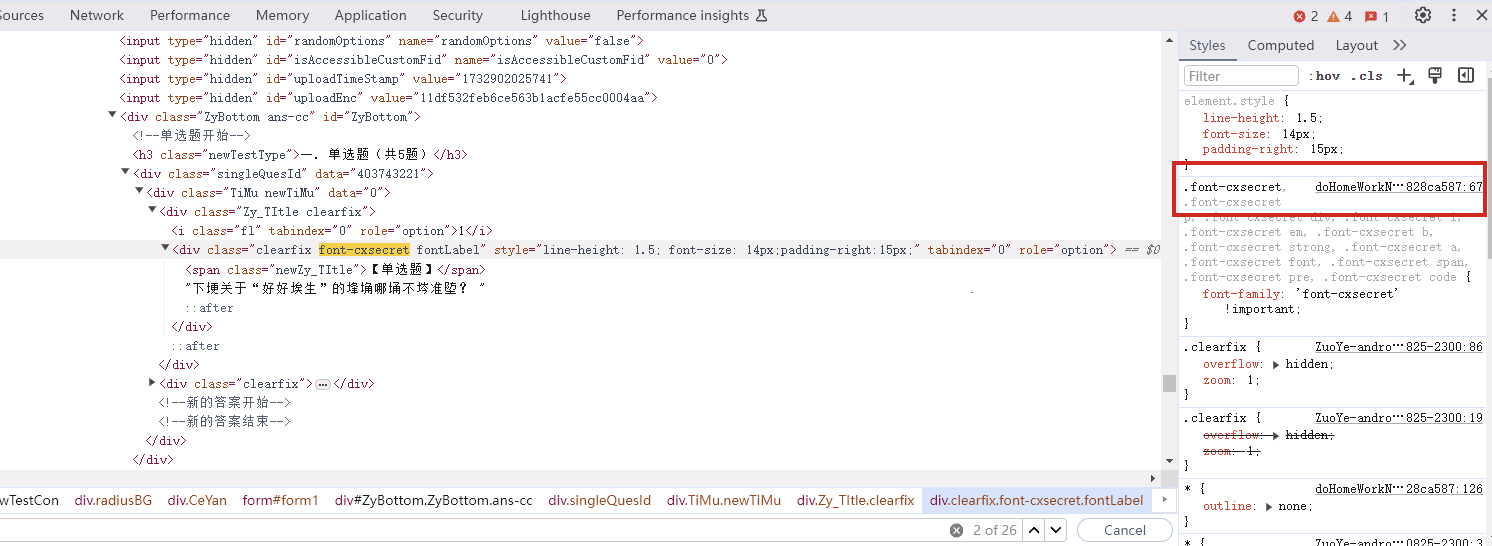 找到之后进去查看 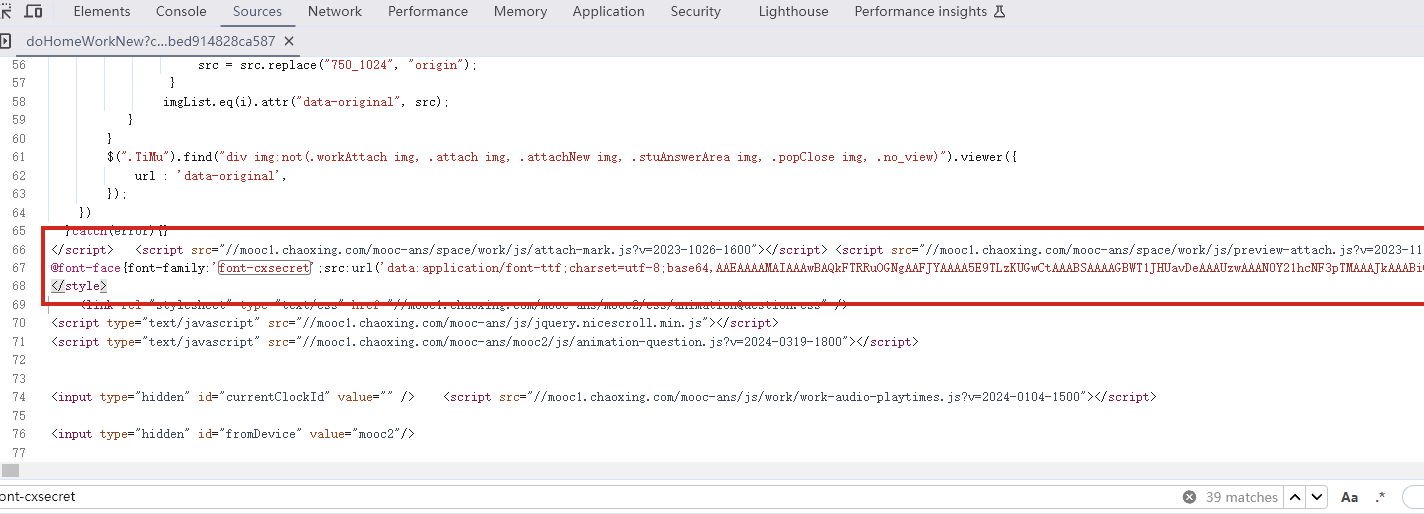 找到了,把里面内容复制下来,掐头去尾,是这样的数据 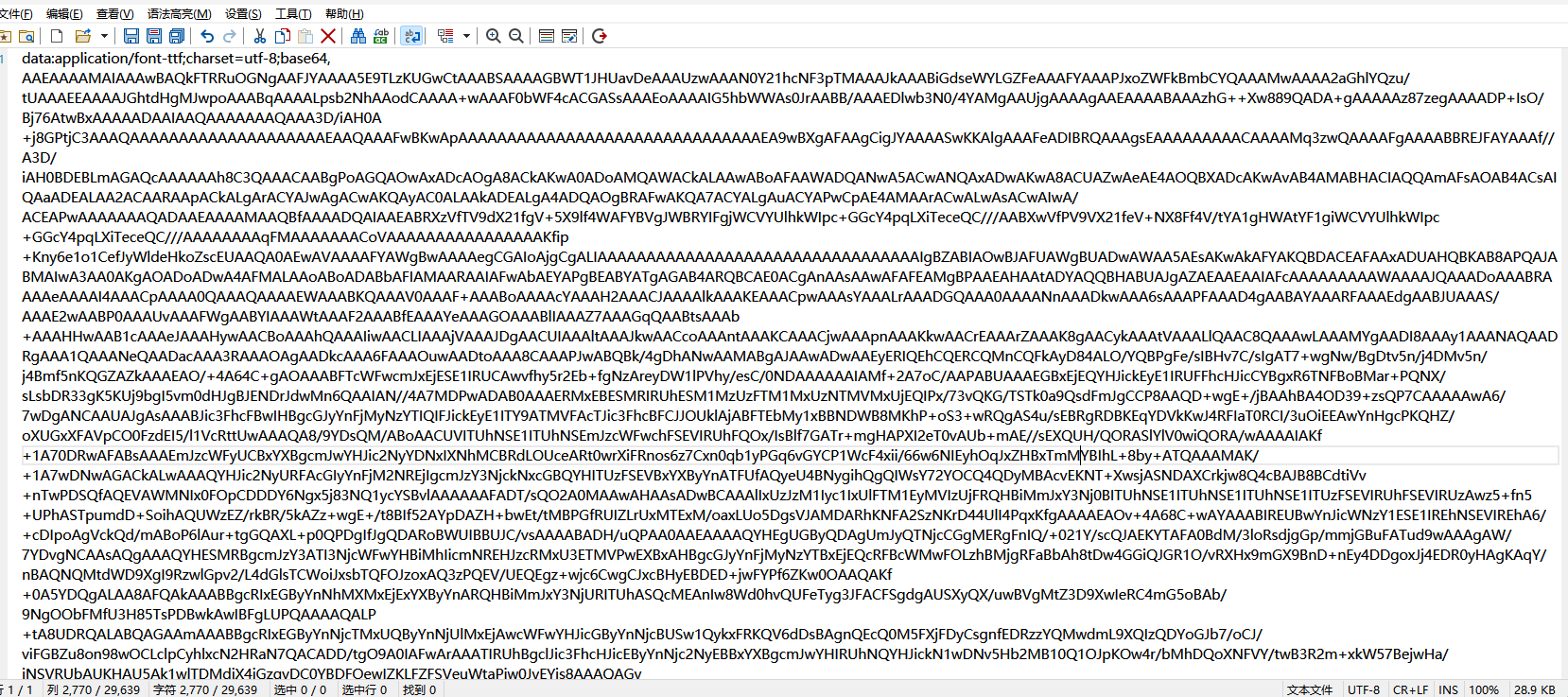 编写脚本进行解码,引号内填写base64编码数据去掉`data:application/font-ttf;charset=utf-8;base64,`的开头声明"  ```python import base64 # Base64编码的字符串 base64_string = "这里填写base64编码数据去掉data:application/font-ttf;charset=utf-8;base64,的开头声明" # 解码Base64字符串 decoded_data = base64.b64decode(base64_string) # 保存为.ttf文件 with open("chaoxing_font.ttf", "wb") as f: f.write(decoded_data) ``` 获得到base64的ttf文件结果 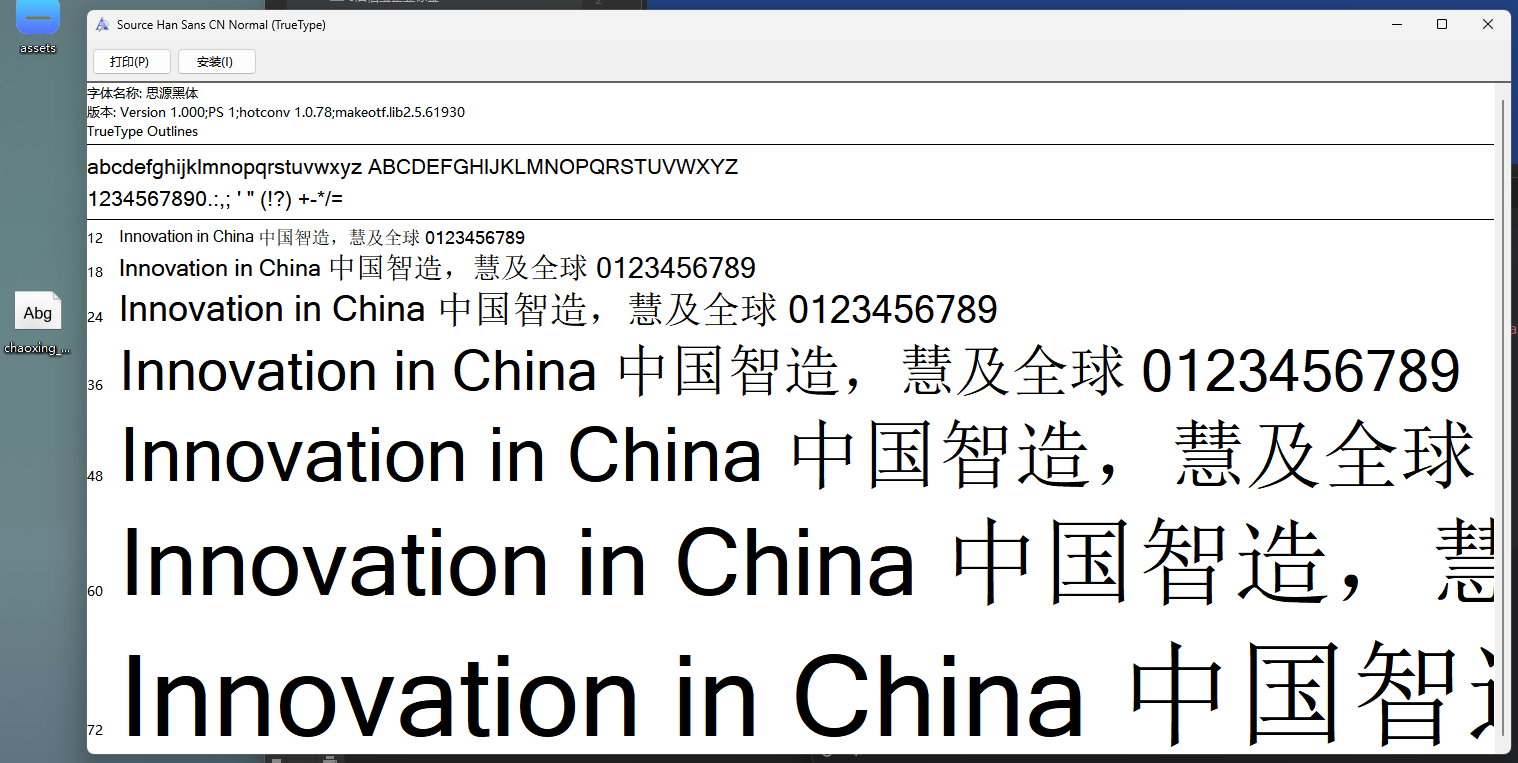 使用字体查看器查看字体 https://www.bejson.com/ui/font/ 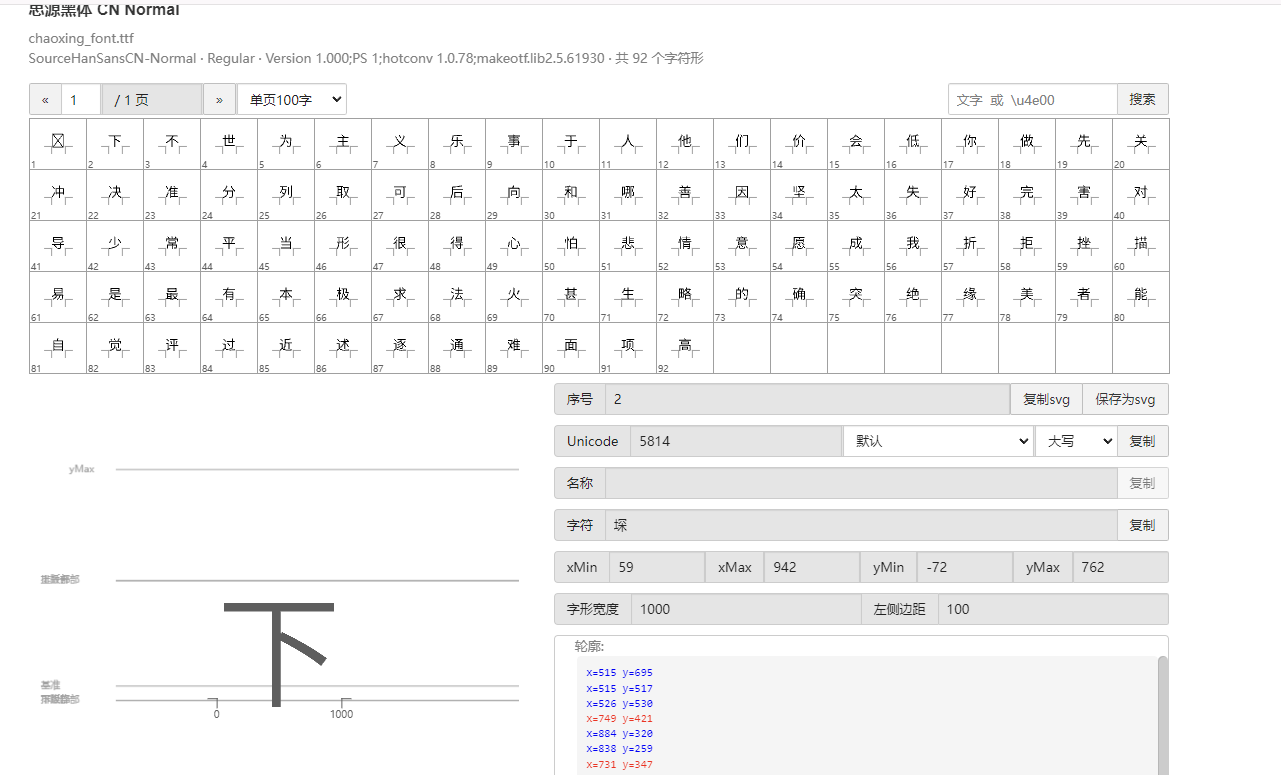 接下来将ttf文件转换成xml文件(python需要安装fontTools) ```python from fontTools.ttLib import TTFont # TTF 文件路径 ttf_path = r"D:\UserData\Desktop\chaoxing_font.ttf" xml_output_path = r"D:\UserData\Desktop\chaoxing_font.xml" # 加载字体文件 font = TTFont(ttf_path) # 保存为 XML 文件 font.saveXML(xml_output_path) print(f"解析完毕") ``` 抽选字体对比一下映射结果对不对(超星的加密是修改了此字体图元数据,显示成未加密的字) 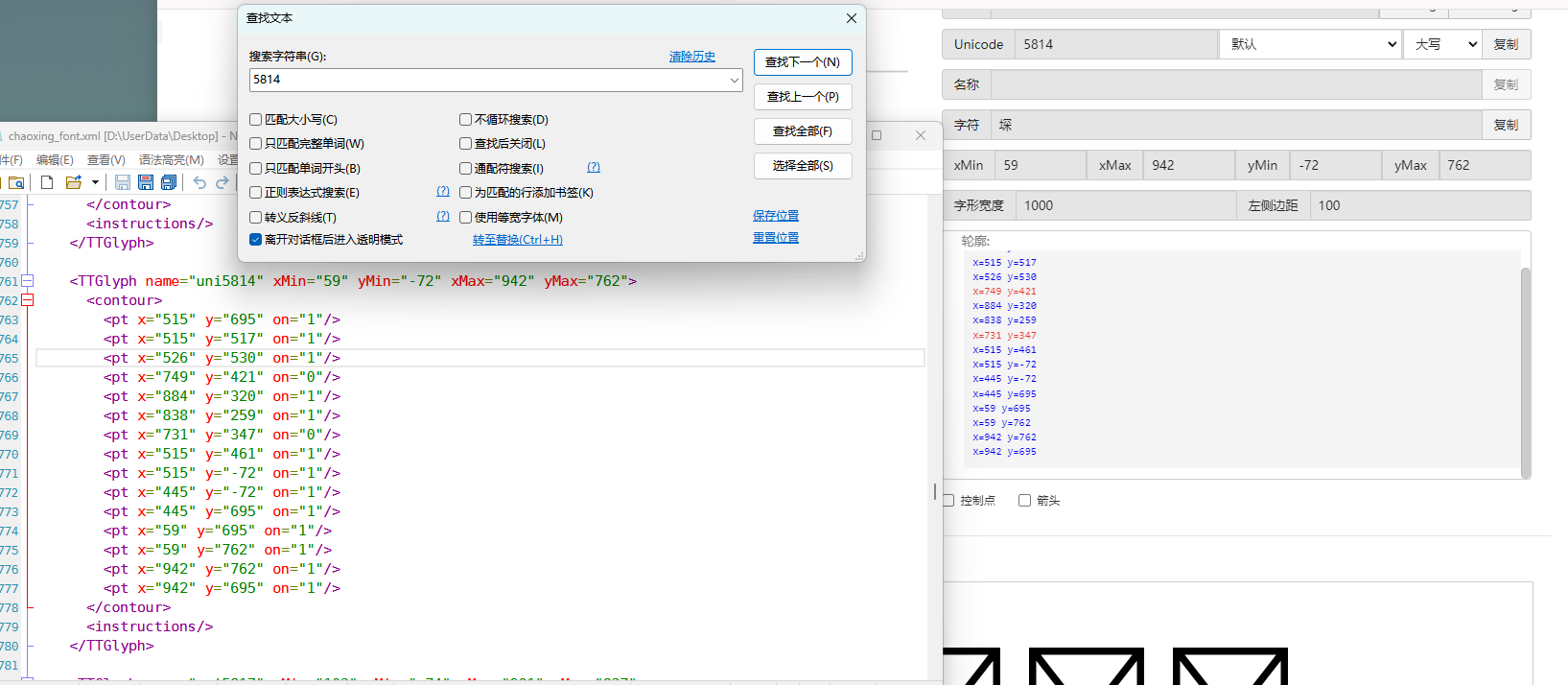 下载原来的字体文件(非超星加密后的文件) 源字体文件对应 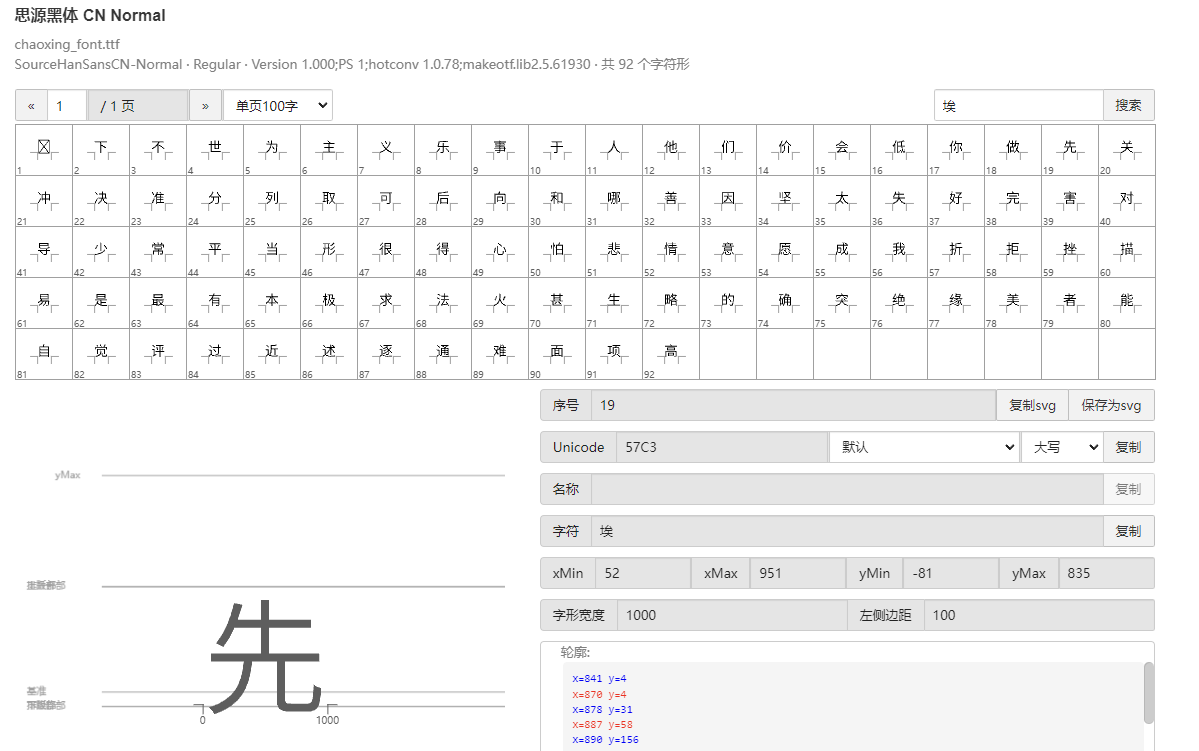 超星加密后字体  也就是说原来的5148对应着57C3 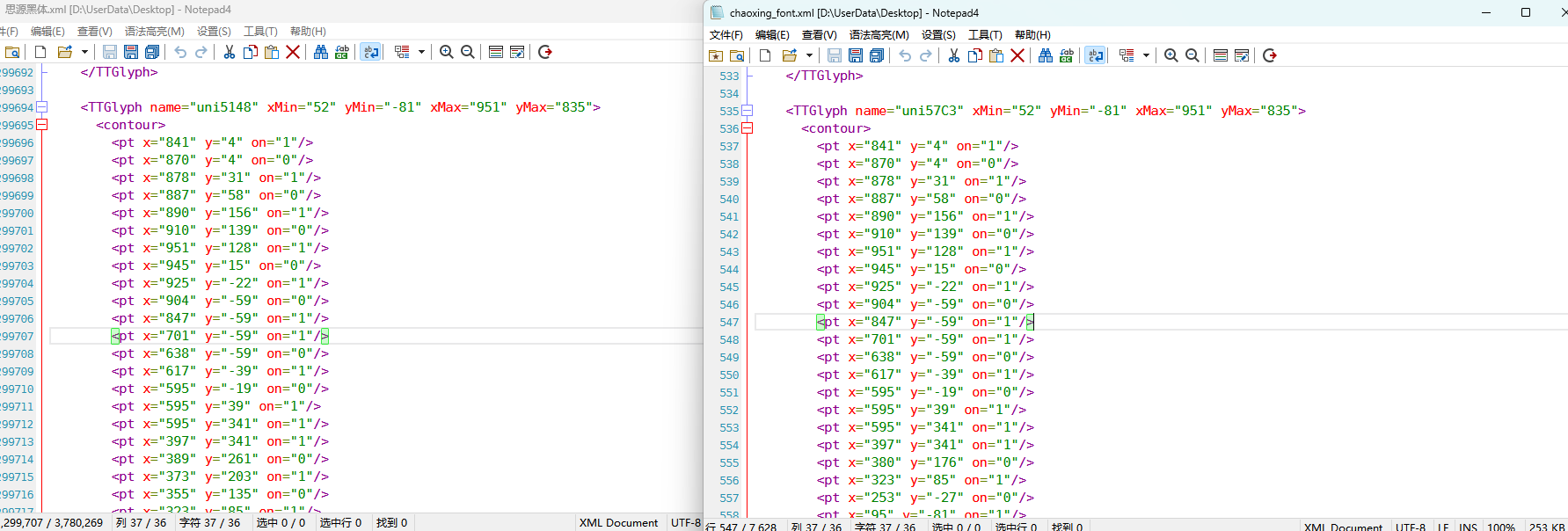 编写对比代码进行测试 ```python import xml.etree.ElementTree as ET import hashlib import json def parse_glyphs(file_path): """ 解析字体文件中的 TTGlyph 信息 """ tree = ET.parse(file_path) root = tree.getroot() glyphs = {} for glyph in root.findall(".//TTGlyph"): name = glyph.get("name") points = [] for pt in glyph.findall(".//pt"): x = pt.get("x") y = pt.get("y") on = pt.get("on") points.append(f"{x}{y}{on}") # 生成轮廓的唯一哈希值 hash_value = hashlib.md5("".join(points).encode('utf-8')).hexdigest() # 截取哈希值的 25-32 位来作为唯一标识 truncated_hash = hash_value[24:32] glyphs[truncated_hash] = name # 使用截取后的哈希值作为键 return glyphs def get_unicode_character(name): """ 根据 glyph 名称(如 uni5148)获取对应汉字 """ if name.startswith("uni"): try: unicode_value = int(name[3:], 16) return chr(unicode_value) except ValueError: return None return None def build_mapping(xml_old_path, xml_cx_path): """ 建立思源黑体和超星字体的对照关系 """ old_glyphs = parse_glyphs(xml_old_path) print(len(old_glyphs)) cx_glyphs = parse_glyphs(xml_cx_path) print(len(cx_glyphs)) mapping = [] for cx_hash, cx_name in cx_glyphs.items(): if cx_hash in old_glyphs: old_name = old_glyphs[cx_hash] character = get_unicode_character(old_name) if character: # 确保是有效汉字 mapping.append({ "chaoxing": cx_name, "si_yuan": { "siyuan_name": old_name, "siyuan_name_value": character } }) return mapping if __name__ == "__main__": xml_old_path = r"D:\UserData\Desktop\思源黑体.xml" xml_cx_path = r"D:\UserData\Desktop\chaoxing_font.xml" result = build_mapping(xml_old_path, xml_cx_path) # 输出到文件 with open("glyph_mapping.json", "w", encoding="utf-8") as f: json.dump(result, f, ensure_ascii=False, indent=4) # 打印部分结果 # print(json.dumps(result[:5], ensure_ascii=False, indent=4)) ``` 生成结果 ```json [ { "chaoxing": "uni57C2", "si_yuan": { "siyuan_name": "uni2FAF", "siyuan_name_value": "⾯" } }, { "chaoxing": "uni57E0", "si_yuan": { "siyuan_name": "uni5584", "siyuan_name_value": "善" } }, { "chaoxing": "uni580F", "si_yuan": { "siyuan_name": "uni4E16", "siyuan_name_value": "世" } }, { "chaoxing": "uni581D", "si_yuan": { "siyuan_name": "uni5BB3", "siyuan_name_value": "害" } }, { "chaoxing": "uni900B", "si_yuan": { "siyuan_name": "uni2F83", "siyuan_name_value": "⾃" } } ] ``` 我采用的字符串是 超星:`下埂关于“好好埃生”的埄埆哪埇不埁准埅?` 思源:`下面关于“好好先生”的描述哪项不太准确?` 结合对照表显示,发现字体字形数据并对不上,查看字体数据,针对“下“字进行分析,发现两边结果并对不上,结果是超星对于字体字形进行了更改,并不是简单的对比字符哈希值就可以对比出来的了。  查看对比效果 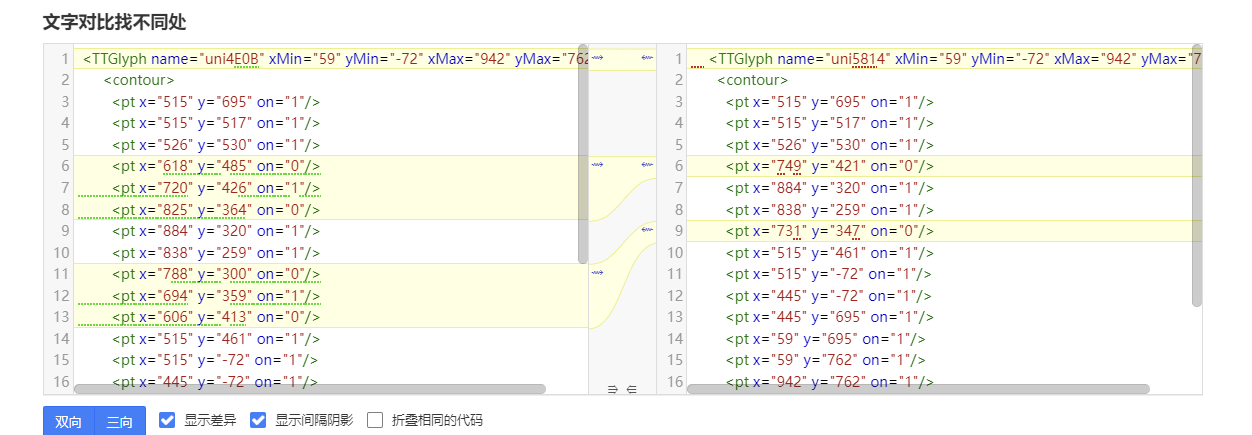 左侧为原版字体,右侧为学习通字体 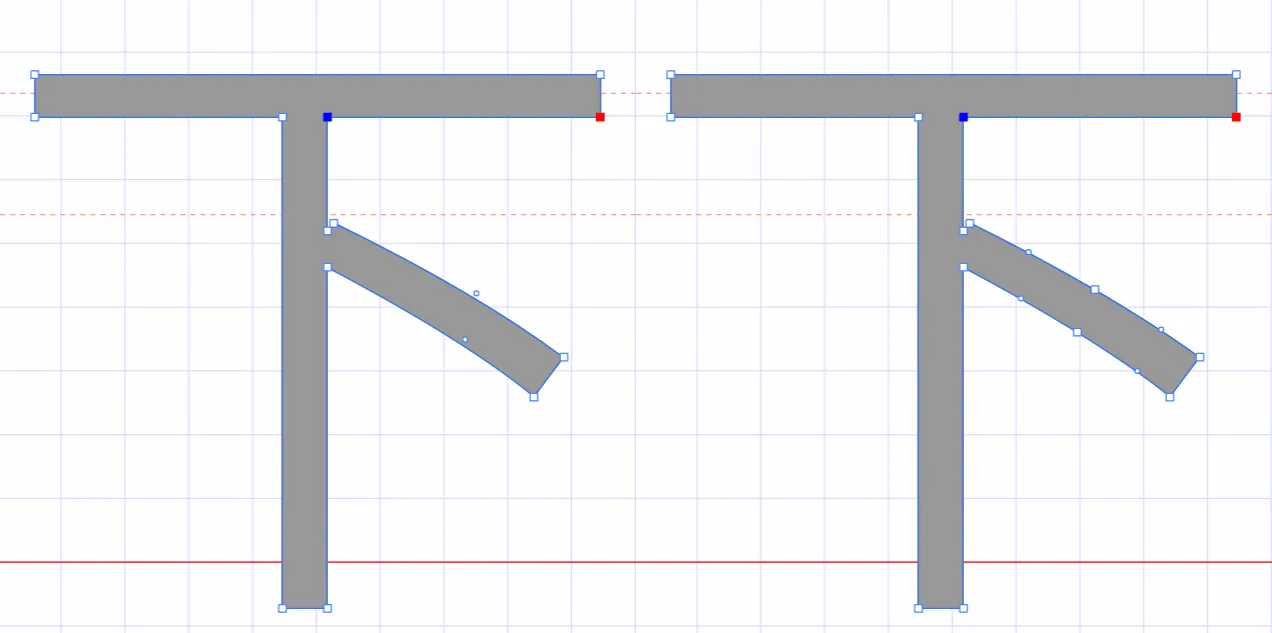 百度到” I Am I“大佬的文章”从学习通复制文字乱码看前端版权保护“找到一定的思路是假设字符的边距是唯一的,好的,那么我们就拼接边距距离。得出以下代码 ```python import xml.etree.ElementTree as ET import hashlib import json def parse_glyphs(file_path): """ 解析字体文件中的 TTGlyph 信息,使用 xMin, yMin, xMax, yMax 作为唯一标识 """ tree = ET.parse(file_path) root = tree.getroot() glyphs = {} for glyph in root.findall(".//TTGlyph"): name = glyph.get("name") # 获取 xMin, yMin, xMax, yMax xMin = glyph.get("xMin") yMin = glyph.get("yMin") xMax = glyph.get("xMax") yMax = glyph.get("yMax") # 使用这四个值拼接成唯一标识符 if xMin and yMin and xMax and yMax: unique_key = f"{xMin}{yMin}{xMax}{yMax}" glyphs[unique_key] = name # 用四个边界值作为唯一键,值为glyph名称 return glyphs # def parse_glyphs(file_path): # """ # 解析字体文件中的 TTGlyph 信息 # """ # tree = ET.parse(file_path) # root = tree.getroot() # # glyphs = {} # # for glyph in root.findall(".//TTGlyph"): # name = glyph.get("name") # points = [] # for pt in glyph.findall(".//pt"): # x = pt.get("x") # y = pt.get("y") # on = pt.get("on") # points.append(f"{x}{y}{on}") # # # 生成轮廓的唯一哈希值 # hash_value = hashlib.md5("".join(points).encode('utf-8')).hexdigest() # glyphs[hash_value] = name # 哈希值对应 glyph 名称 # # return glyphs def get_unicode_character(name): """ 根据 glyph 名称(如 uni5148)获取对应汉字 """ if name.startswith("uni"): try: unicode_value = int(name[3:], 16) return chr(unicode_value) except ValueError: return None return None def build_mapping(xml_old_path, xml_cx_path): """ 建立思源黑体和超星字体的对照关系 """ old_glyphs = parse_glyphs(xml_old_path) # print(len(old_glyphs)) cx_glyphs = parse_glyphs(xml_cx_path) # print(len(cx_glyphs)) # print(cx_glyphs) mapping = [] for cx_hash, cx_name in cx_glyphs.items(): if cx_hash in old_glyphs: old_name = old_glyphs[cx_hash] character = get_unicode_character(old_name) if cx_name == 'uni5814': print(cx_hash) print(old_name) if character: # 确保是有效汉字 mapping.append({ "chaoxing": cx_name, "si_yuan" : { "siyuan_name": old_name, "siyuan_name_value": character } }) return mapping if __name__ == "__main__": xml_old_path = r"D:\UserData\Desktop\思源黑体.xml" xml_cx_path = r"D:\UserData\Desktop\chaoxing_font.xml" result = build_mapping(xml_old_path, xml_cx_path) # 输出到文件 with open("glyph_mapping.json", "w", encoding="utf-8") as f: json.dump(result, f, ensure_ascii=False, indent=4) # 打印部分结果 # print(json.dumps(result[:5], ensure_ascii=False, indent=4)) ``` 再通过匹配结果进行查看数据 ```python import json # 读取json def load_mapping(file_path): with open(file_path, "r", encoding="utf-8") as f: return json.load(f) # 获取字符对应的 uni 名称 def get_uni_name(character, mapping): unicode_name = f"uni{ord(character):X}" # print(unicode_name) for entry in mapping: if entry["chaoxing"] == unicode_name: return entry return None # 解析字符串 def parse_code(code, mapping): result = [] for char in code: mapping_entry = get_uni_name(char, mapping) if mapping_entry: result.append({ "char": char, "message": mapping_entry["si_yuan"]['siyuan_name_value'] }) else: result.append({ "char": char, "message": char }) return result # 测试代码 if __name__ == "__main__": # 读取字形映射 glyph_mapping_file = "glyph_mapping.json" mapping = load_mapping(glyph_mapping_file) # 示例字符串 code = '下埂关于“好好埃生”的埄埆哪埇不埁准埅?' # 解析字符串 parsed_result = parse_code(code, mapping) # 输出解析结果 # for item in parsed_result: # print(item) print(f'超星字体:{code}') siyuan_font = ''.join([item['message'] for item in parsed_result]) print(f'思源字体:{siyuan_font}') ``` 得出结果 ```shel 超星字体:下埂关于“好好埃生”的埄埆哪埇不埁准埅? 思源字体:下⾯关于“好好先生”的描述哪项不太准确? ``` 在大佬的测试中,是可以确定90%左右的字符数据的。如果您不想看了,到这里就可以了,基本满足所有的效果了。 然后由于最近领导给我一些任务就是比较两个字符串的相似度,通过这个启发就想通过xy向量计算字符字形的相似度。得出以下代码,首先针对”下”字进行数据测试 1. **归一化**:将所有点归一化到相同的尺度。(如果不归一,DTW有要求长度一样,会报错) **归一化点集**(Normalization of points)是指将原始点集中的每个点的坐标变换到一个特定的标准范围,以消除由于坐标范围不同而引起的差异,从而使得数据的比较更加公正和一致。具体而言,在这段代码中,归一化的目标是将每个点的坐标缩放到 `[0, 1]` 的范围内。 **为什么要进行归一化?** 在计算点集之间的相似度时(如使用动态时间规整 DTW),不同的点集可能有不同的坐标范围或单位。如果不进行归一化,可能会因为坐标差异较大,导致计算出的相似度偏差较大。归一化的过程能够消除这种影响,让两个点集具有相同的尺度,从而公平地比较它们之间的相似性。 **举个例子:** 假设有一个点集: ```python points = [(10, 20), (30, 40), (50, 60), (70, 80)] ``` 经过归一化处理后: - 最小值:`min_x = 10`, `min_y = 20` - 最大值:`max_x = 70`, `max_y = 80` 每个点将会变成: - `(10, 20)` 变成 `(0, 0)` - `(30, 40)` 变成 `(0.333, 0.333)` - `(50, 60)` 变成 `(0.666, 0.666)` - `(70, 80)` 变成 `(1, 1)` 最终,这些点就会被归一化到 `[0, 1]` 的范围内,这样它们的尺度是一致的,适合用于后续的相似度计算。归一化的目的是消除不同点集之间的坐标尺度差异,使得不同的点集可以在相同的尺度下进行比较。通过这种方式,我们可以更加公平地计算它们之间的相似度,而不会因为坐标的差异导致错误的比较结果。 2. **使用DTW进行点对齐**:保持原有的DTW对齐方法。 这里计算两个点集的相似度分数,通过DTW距离计算得出一个0~1的相似度分数。1完全相似,0完全不一样。 函数使用 `fastdtw` 函数计算归一化后的两个点集之间的 **DTW 距离**。DTW 是一种衡量两组时间序列相似度的算法,常用于处理不等长、速度不同的序列数据。在这里,它也可以用于比较两个二维点集的相似度。 3. **计算相似度**:基于对齐后的点集计算相似度。 ```python import numpy as np from fastdtw import fastdtw from scipy.spatial.distance import euclidean # 假设我们已经有了两个字形的数据 ttglyph_superstar = [ (515, 695), (515, 517), (526, 530), (749, 421), (884, 320), (838, 259), (731, 347), (515, 461), (515, -72), (445, -72), (445, 695), (59, 695), (59, 762), (942, 762), (942, 695) ] ttglyph_sourcehan = [ (515, 695), (515, 517), (526, 530), (618, 485), (720, 426), (825, 364), (884, 320), (838, 259), (788, 300), (694, 359), (606, 413), (515, 461), (515, -72), (445, -72), (445, 695), (59, 695), (59, 762), (942, 762), (942, 695) ] # 转换为numpy数组 points1 = np.array(ttglyph_superstar) points2 = np.array(ttglyph_sourcehan) def normalize_points(points): """ 归一化点集 """ if len(points) == 0: # 检查点集是否为空 return [] points = np.array(points) # 将点集转换为NumPy数组 min_x, min_y = np.min(points, axis=0) max_x, max_y = np.max(points, axis=0) # 防止除以零 if max_x == min_x: max_x = min_x + 1 if max_y == min_y: max_y = min_y + 1 normalized_points = (points - [min_x, min_y]) / [max_x - min_x, max_y - min_y] return normalized_points def calculate_similarity(points1, points2): """ 使用DTW计算两个点集之间的相似度 """ points1_normalized = normalize_points(points1) points2_normalized = normalize_points(points2) if len(points1_normalized) == 0 or len(points2_normalized) == 0: return 0.0 # 如果任一点集为空,相似度为0 #distance 是 DTW 算法计算出来的总距离,表示两个点集的整体差异。 #path 是 DTW 算法找到的最佳对齐路径,指示了如何从 points1 映射到 points2。 distance, path = fastdtw(points1_normalized, points2_normalized, dist=euclidean) # DTW 算法会计算出一组“对齐”路径,通过这个路径可以重新排列两个点集,使它们更好地对齐。根据 path 的内容,分别从 points1_normalized 和 points2_normalized 中提取对齐后的点集。 aligned_points1 = [points1_normalized[i] for i, _ in path] aligned_points2 = [points2_normalized[j] for _, j in path] # 计算对齐点之间的欧几里得距离,在最佳对齐下,每对点之间的差异。np.linalg.norm 计算的是两点之间的欧几里得距离 distances = [np.linalg.norm(np.array(p1) - np.array(p2)) for p1, p2 in zip(aligned_points1, aligned_points2)] # 算出所有欧氏距离去平局书,得出平均欧氏距距离 average_distance = np.mean(distances) similarity_score = 1 / (1 + average_distance) return similarity_score print(f"Similarity score: {calculate_similarity(points2,points1)}") ``` 得出结果 ```shell Similarity score: 0.975700703557036 ``` 发现相似度还是很高的,这里是需要忽略字体的风格的,和笔画的这些。 好的,可以通过这种相似度算法去核对超星字体对应的元数据了。 ```python import xml.etree.ElementTree as ET import json import numpy as np from fastdtw import fastdtw from scipy.spatial.distance import euclidean from tqdm import tqdm def parse_glyphs(file_path): """ 解析字体文件中的 TTGlyph 信息 """ tree = ET.parse(file_path) root = tree.getroot() glyphs = {} for glyph in root.findall(".//TTGlyph"): name = glyph.get("name") points = [] for pt in glyph.findall(".//pt"): x = int(pt.get("x")) y = int(pt.get("y")) on = int(pt.get("on", 0)) # 默认值为0,如果不存在则设为0 points.append((x, y)) # 将点集转换为字符串,作为字典的键 key = str(points) glyphs[key] = name return glyphs def get_unicode_character(name): """ 根据 glyph 名称(如 uni5148)获取对应汉字 """ if name.startswith("uni"): try: unicode_value = int(name[3:], 16) return chr(unicode_value) except ValueError: return None return None def normalize_points(points): """ 归一化点集 """ if not points: # 检查点集是否为空 return [] points = np.array(points) # 将点集转换为NumPy数组 min_x, min_y = np.min(points, axis=0) max_x, max_y = np.max(points, axis=0) # 防止除以零 if max_x == min_x: max_x = min_x + 1 if max_y == min_y: max_y = min_y + 1 normalized_points = (points - [min_x, min_y]) / [max_x - min_x, max_y - min_y] return normalized_points def calculate_similarity(points1, points2): """ 使用DTW计算两个点集之间的相似度 """ points1_normalized = normalize_points(points1) points2_normalized = normalize_points(points2) if len(points1_normalized) == 0 or len(points2_normalized) == 0: return 0.0 # 如果任一点集为空,相似度为0 distance, path = fastdtw(points1_normalized, points2_normalized, dist=euclidean) aligned_points1 = [points1_normalized[i] for i, _ in path] aligned_points2 = [points2_normalized[j] for _, j in path] distances = [np.linalg.norm(np.array(p1) - np.array(p2)) for p1, p2 in zip(aligned_points1, aligned_points2)] average_distance = np.mean(distances) similarity_score = 1 / (1 + average_distance) return similarity_score def build_mapping(xml_old_path, xml_cx_path): """ 建立思源黑体和超星字体的对照关系 """ old_glyphs = parse_glyphs(xml_old_path) print(f'思源字体:{len(old_glyphs)}') cx_glyphs = parse_glyphs(xml_cx_path) print(f'超星字体:{len(cx_glyphs)}') mapping = [] total_combinations = len(old_glyphs) * len(cx_glyphs) with tqdm(total=total_combinations, desc="Processing") as pbar: for old_key, old_name in old_glyphs.items(): for cx_key, cx_name in cx_glyphs.items(): similarity = calculate_similarity(eval(old_key), eval(cx_key)) if similarity >= 0.9: mapping.append({ "chaoxing": { "cx_name": cx_name, "cx_character": get_unicode_character(cx_name) }, "si_yuan": { "sy_name": old_name, "sy_character": get_unicode_character(old_name) }, "similarity": similarity }) pbar.update(1) return mapping if __name__ == "__main__": xml_old_path = r"D:\UserData\Desktop\思源黑体.xml" xml_cx_path = r"D:\UserData\Desktop\chaoxing_font.xml" result = build_mapping(xml_old_path, xml_cx_path) # 输出到文件 with open("glyph_mapping2.json", "w", encoding="utf-8") as f: json.dump(result, f, ensure_ascii=False, indent=4) # print(json.dumps(result[:5], ensure_ascii=False, indent=4)) ``` 但是运行效果不如人意 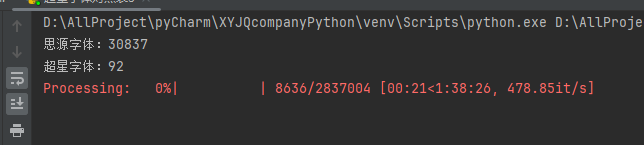 这么长的时间肯定是不能忍的,所有采用多线程的处理方式,cpu就应该忙起来了。 ```python from concurrent.futures import ProcessPoolExecutor, as_completed import json import numpy as np from fastdtw import fastdtw from scipy.spatial.distance import euclidean from tqdm import tqdm import xml.etree.ElementTree as ET # 其他函数不变,保持之前的代码 def calculate_similarity(points1, points2): """ 使用DTW计算两个点集之间的相似度 """ points1_normalized = normalize_points(points1) points2_normalized = normalize_points(points2) if len(points1_normalized) == 0 or len(points2_normalized) == 0: return 0.0 # 如果任一点集为空,相似度为0 distance, path = fastdtw(points1_normalized, points2_normalized, dist=euclidean) aligned_points1 = [points1_normalized[i] for i, _ in path] aligned_points2 = [points2_normalized[j] for _, j in path] distances = [np.linalg.norm(np.array(p1) - np.array(p2)) for p1, p2 in zip(aligned_points1, aligned_points2)] average_distance = np.mean(distances) similarity_score = 1 / (1 + average_distance) return similarity_score def normalize_points(points): """ 归一化点集 """ if not points: # 检查点集是否为空 return [] points = np.array(points) # 将点集转换为NumPy数组 min_x, min_y = np.min(points, axis=0) max_x, max_y = np.max(points, axis=0) # 防止除以零 if max_x == min_x: max_x = min_x + 1 if max_y == min_y: max_y = min_y + 1 normalized_points = (points - [min_x, min_y]) / [max_x - min_x, max_y - min_y] return normalized_points def parallel_calculate_similarity(old_key, old_name, cx_glyphs): """ 并行计算相似度 """ results = [] for cx_key, cx_name in cx_glyphs.items(): similarity = calculate_similarity(eval(old_key), eval(cx_key)) if similarity >= 0.9: results.append({ "chaoxing": { "cx_name": cx_name, "cx_character": get_unicode_character(cx_name) }, "si_yuan": { "sy_name": old_name, "sy_character": get_unicode_character(old_name) }, "similarity": similarity }) return results def get_unicode_character(name): """ 根据 glyph 名称(如 uni5148)获取对应汉字 """ if name.startswith("uni"): try: unicode_value = int(name[3:], 16) return chr(unicode_value) except ValueError: return None return None def parse_glyphs(file_path): """ 解析字体文件中的 TTGlyph 信息 """ tree = ET.parse(file_path) root = tree.getroot() glyphs = {} for glyph in root.findall(".//TTGlyph"): name = glyph.get("name") points = [] for pt in glyph.findall(".//pt"): x = int(pt.get("x")) y = int(pt.get("y")) on = int(pt.get("on", 0)) # 默认值为0,如果不存在则设为0 points.append((x, y)) # 将点集转换为字符串,作为字典的键 key = str(points) glyphs[key] = name return glyphs def build_mapping_parallel(xml_old_path, xml_cx_path): """ 并行建立思源黑体和超星字体的对照关系 """ old_glyphs = parse_glyphs(xml_old_path) print(f'思源字体:{len(old_glyphs)}') cx_glyphs = parse_glyphs(xml_cx_path) print(f'超星字体:{len(cx_glyphs)}') mapping = [] # 使用进程池进行并行处理 with ProcessPoolExecutor() as executor: futures = [] # 为每个思源字体字形提交任务 for old_key, old_name in old_glyphs.items(): futures.append(executor.submit(parallel_calculate_similarity, old_key, old_name, cx_glyphs)) # 通过 as_completed 获取计算结果 for future in tqdm(as_completed(futures), total=len(futures), desc="Processing"): mapping.extend(future.result()) return mapping if __name__ == "__main__": xml_old_path = r"D:\UserData\Desktop\思源黑体.xml" xml_cx_path = r"D:\UserData\Desktop\chaoxing_font.xml" result = build_mapping_parallel(xml_old_path, xml_cx_path) # 输出到文件 with open("glyph_mapping_parallel.json", "w", encoding="utf-8") as f: json.dump(result, f, ensure_ascii=False, indent=4) # 打印部分结果 print(json.dumps(result[:5], ensure_ascii=False, indent=4)) ``` 这样处理时间来到了半小时(不过cpu要满了),因为我要求把大于0.9的数据全弄出来了,所以会有很多重复的字形数据。这里还需要取出相似度最高的那一个字形数据。 ```python import json # 读取保存的结果文件并生成包含所有相似度最高数据的 high.json 文件 def find_most_similar_for_all(result_file="glyph_mapping_parallel.json", output_file="high.json"): # 读取 JSON 数据 with open(result_file, "r", encoding="utf-8") as f: data = json.load(f) # 用于存储每个 chaoxing 对应的最相似的 si_yuan 对照项 highest_similarity_entries = {} # 遍历所有条目,找出每个 chaoxing 字符对应的最相似的 si_yuan 对照项 for entry in data: cx_name = entry["chaoxing"]["cx_name"] similarity = entry["similarity"] # 如果该 cx_name 没有出现过,或者当前相似度更高,更新最相似的条目 if cx_name not in highest_similarity_entries or similarity > highest_similarity_entries[cx_name]["similarity"]: highest_similarity_entries[cx_name] = entry # print(len(highest_similarity_entries)) # 将结果保存到 high.json 文件 with open(output_file, "w", encoding="utf-8") as f: json.dump(list(highest_similarity_entries.values()), f, ensure_ascii=False, indent=4) print(f"已将结果保存到 {output_file}") # 调用函数,生成 high.json 文件 find_most_similar_for_all() ``` 至此,我们以及彻底完成了映射表的制作。然后拿数据跑一下进行测试 ```python import json # 读取 high.json 文件并加载数据 def load_high_json(file_path="high.json"): with open(file_path, "r", encoding="utf-8") as f: return json.load(f) # 根据 high.json 匹配字符串中的每个字符,返回结果字符串 def match_string_with_high_json(code, high_json_data): result = [] for char in code: # 遍历 high.json 中的所有项,查找匹配的 cx_character matched = False for entry in high_json_data: if entry["chaoxing"]["cx_character"] == char: # 根据需要将匹配的结果拼接成字符串 result.append(entry["si_yuan"]["sy_character"]) # 使用 si_yuan 对应的字符 matched = True break if not matched: # 如果没有找到匹配的项,保留原字符 result.append(char) # 将匹配结果列表合并成一个字符串 return ''.join(result) # 示例字符串 code = '下埂关于“好好埃生”的埄埆哪埇不埁准埅?' # 加载 high.json 数据 high_json_data = load_high_json() # 匹配字符串 result_string = match_string_with_high_json(code, high_json_data) print(f'超星字体:{code}') print(f'思源字体:{result_string}') ``` 得出结果 ```shell 超星字体:下埂关于“好好埃生”的埄埆哪埇不埁准埅? 思源字体:下⾯关于“好好先生”的描述哪项不太准确? ``` 好的,已经可以了,这里关于超星字体的时候,有个疑问就是为什么每个页面加载页面的字体,不能拿到全部的,我这个不知道咋弄,很困扰我,希望有大佬可以帮忙解释一下。 至此,文章彻底结束。 参考文章: 关于超星学习通网页版字体加密分析 :https://www.52pojie.cn/thread-1631357-4-1.html 从学习通复制文字乱码看前端版权保护:https://5ime.cn/xxt_font.html Loading... 右键网页检查  搜索页面和这个相关的从而定位到引入文件  查找,一眼Base64编码的字体文件,通过这个编码数据解码获得原字体文件  找到之后进去查看  找到了,把里面内容复制下来,掐头去尾,是这样的数据  编写脚本进行解码,引号内填写base64编码数据去掉`data:application/font-ttf;charset=utf-8;base64,`的开头声明"  ```python import base64 # Base64编码的字符串 base64_string = "这里填写base64编码数据去掉data:application/font-ttf;charset=utf-8;base64,的开头声明" # 解码Base64字符串 decoded_data = base64.b64decode(base64_string) # 保存为.ttf文件 with open("chaoxing_font.ttf", "wb") as f: f.write(decoded_data) ``` 获得到base64的ttf文件结果  使用字体查看器查看字体 https://www.bejson.com/ui/font/  接下来将ttf文件转换成xml文件(python需要安装fontTools) ```python from fontTools.ttLib import TTFont # TTF 文件路径 ttf_path = r"D:\UserData\Desktop\chaoxing_font.ttf" xml_output_path = r"D:\UserData\Desktop\chaoxing_font.xml" # 加载字体文件 font = TTFont(ttf_path) # 保存为 XML 文件 font.saveXML(xml_output_path) print(f"解析完毕") ``` 抽选字体对比一下映射结果对不对(超星的加密是修改了此字体图元数据,显示成未加密的字)  下载原来的字体文件(非超星加密后的文件) 源字体文件对应  超星加密后字体  也就是说原来的5148对应着57C3  编写对比代码进行测试 ```python import xml.etree.ElementTree as ET import hashlib import json def parse_glyphs(file_path): """ 解析字体文件中的 TTGlyph 信息 """ tree = ET.parse(file_path) root = tree.getroot() glyphs = {} for glyph in root.findall(".//TTGlyph"): name = glyph.get("name") points = [] for pt in glyph.findall(".//pt"): x = pt.get("x") y = pt.get("y") on = pt.get("on") points.append(f"{x}{y}{on}") # 生成轮廓的唯一哈希值 hash_value = hashlib.md5("".join(points).encode('utf-8')).hexdigest() # 截取哈希值的 25-32 位来作为唯一标识 truncated_hash = hash_value[24:32] glyphs[truncated_hash] = name # 使用截取后的哈希值作为键 return glyphs def get_unicode_character(name): """ 根据 glyph 名称(如 uni5148)获取对应汉字 """ if name.startswith("uni"): try: unicode_value = int(name[3:], 16) return chr(unicode_value) except ValueError: return None return None def build_mapping(xml_old_path, xml_cx_path): """ 建立思源黑体和超星字体的对照关系 """ old_glyphs = parse_glyphs(xml_old_path) print(len(old_glyphs)) cx_glyphs = parse_glyphs(xml_cx_path) print(len(cx_glyphs)) mapping = [] for cx_hash, cx_name in cx_glyphs.items(): if cx_hash in old_glyphs: old_name = old_glyphs[cx_hash] character = get_unicode_character(old_name) if character: # 确保是有效汉字 mapping.append({ "chaoxing": cx_name, "si_yuan": { "siyuan_name": old_name, "siyuan_name_value": character } }) return mapping if __name__ == "__main__": xml_old_path = r"D:\UserData\Desktop\思源黑体.xml" xml_cx_path = r"D:\UserData\Desktop\chaoxing_font.xml" result = build_mapping(xml_old_path, xml_cx_path) # 输出到文件 with open("glyph_mapping.json", "w", encoding="utf-8") as f: json.dump(result, f, ensure_ascii=False, indent=4) # 打印部分结果 # print(json.dumps(result[:5], ensure_ascii=False, indent=4)) ``` 生成结果 ```json [ { "chaoxing": "uni57C2", "si_yuan": { "siyuan_name": "uni2FAF", "siyuan_name_value": "⾯" } }, { "chaoxing": "uni57E0", "si_yuan": { "siyuan_name": "uni5584", "siyuan_name_value": "善" } }, { "chaoxing": "uni580F", "si_yuan": { "siyuan_name": "uni4E16", "siyuan_name_value": "世" } }, { "chaoxing": "uni581D", "si_yuan": { "siyuan_name": "uni5BB3", "siyuan_name_value": "害" } }, { "chaoxing": "uni900B", "si_yuan": { "siyuan_name": "uni2F83", "siyuan_name_value": "⾃" } } ] ``` 我采用的字符串是 超星:`下埂关于“好好埃生”的埄埆哪埇不埁准埅?` 思源:`下面关于“好好先生”的描述哪项不太准确?` 结合对照表显示,发现字体字形数据并对不上,查看字体数据,针对“下“字进行分析,发现两边结果并对不上,结果是超星对于字体字形进行了更改,并不是简单的对比字符哈希值就可以对比出来的了。  查看对比效果  左侧为原版字体,右侧为学习通字体  百度到” I Am I“大佬的文章”从学习通复制文字乱码看前端版权保护“找到一定的思路是假设字符的边距是唯一的,好的,那么我们就拼接边距距离。得出以下代码 ```python import xml.etree.ElementTree as ET import hashlib import json def parse_glyphs(file_path): """ 解析字体文件中的 TTGlyph 信息,使用 xMin, yMin, xMax, yMax 作为唯一标识 """ tree = ET.parse(file_path) root = tree.getroot() glyphs = {} for glyph in root.findall(".//TTGlyph"): name = glyph.get("name") # 获取 xMin, yMin, xMax, yMax xMin = glyph.get("xMin") yMin = glyph.get("yMin") xMax = glyph.get("xMax") yMax = glyph.get("yMax") # 使用这四个值拼接成唯一标识符 if xMin and yMin and xMax and yMax: unique_key = f"{xMin}{yMin}{xMax}{yMax}" glyphs[unique_key] = name # 用四个边界值作为唯一键,值为glyph名称 return glyphs # def parse_glyphs(file_path): # """ # 解析字体文件中的 TTGlyph 信息 # """ # tree = ET.parse(file_path) # root = tree.getroot() # # glyphs = {} # # for glyph in root.findall(".//TTGlyph"): # name = glyph.get("name") # points = [] # for pt in glyph.findall(".//pt"): # x = pt.get("x") # y = pt.get("y") # on = pt.get("on") # points.append(f"{x}{y}{on}") # # # 生成轮廓的唯一哈希值 # hash_value = hashlib.md5("".join(points).encode('utf-8')).hexdigest() # glyphs[hash_value] = name # 哈希值对应 glyph 名称 # # return glyphs def get_unicode_character(name): """ 根据 glyph 名称(如 uni5148)获取对应汉字 """ if name.startswith("uni"): try: unicode_value = int(name[3:], 16) return chr(unicode_value) except ValueError: return None return None def build_mapping(xml_old_path, xml_cx_path): """ 建立思源黑体和超星字体的对照关系 """ old_glyphs = parse_glyphs(xml_old_path) # print(len(old_glyphs)) cx_glyphs = parse_glyphs(xml_cx_path) # print(len(cx_glyphs)) # print(cx_glyphs) mapping = [] for cx_hash, cx_name in cx_glyphs.items(): if cx_hash in old_glyphs: old_name = old_glyphs[cx_hash] character = get_unicode_character(old_name) if cx_name == 'uni5814': print(cx_hash) print(old_name) if character: # 确保是有效汉字 mapping.append({ "chaoxing": cx_name, "si_yuan" : { "siyuan_name": old_name, "siyuan_name_value": character } }) return mapping if __name__ == "__main__": xml_old_path = r"D:\UserData\Desktop\思源黑体.xml" xml_cx_path = r"D:\UserData\Desktop\chaoxing_font.xml" result = build_mapping(xml_old_path, xml_cx_path) # 输出到文件 with open("glyph_mapping.json", "w", encoding="utf-8") as f: json.dump(result, f, ensure_ascii=False, indent=4) # 打印部分结果 # print(json.dumps(result[:5], ensure_ascii=False, indent=4)) ``` 再通过匹配结果进行查看数据 ```python import json # 读取json def load_mapping(file_path): with open(file_path, "r", encoding="utf-8") as f: return json.load(f) # 获取字符对应的 uni 名称 def get_uni_name(character, mapping): unicode_name = f"uni{ord(character):X}" # print(unicode_name) for entry in mapping: if entry["chaoxing"] == unicode_name: return entry return None # 解析字符串 def parse_code(code, mapping): result = [] for char in code: mapping_entry = get_uni_name(char, mapping) if mapping_entry: result.append({ "char": char, "message": mapping_entry["si_yuan"]['siyuan_name_value'] }) else: result.append({ "char": char, "message": char }) return result # 测试代码 if __name__ == "__main__": # 读取字形映射 glyph_mapping_file = "glyph_mapping.json" mapping = load_mapping(glyph_mapping_file) # 示例字符串 code = '下埂关于“好好埃生”的埄埆哪埇不埁准埅?' # 解析字符串 parsed_result = parse_code(code, mapping) # 输出解析结果 # for item in parsed_result: # print(item) print(f'超星字体:{code}') siyuan_font = ''.join([item['message'] for item in parsed_result]) print(f'思源字体:{siyuan_font}') ``` 得出结果 ```shel 超星字体:下埂关于“好好埃生”的埄埆哪埇不埁准埅? 思源字体:下⾯关于“好好先生”的描述哪项不太准确? ``` 在大佬的测试中,是可以确定90%左右的字符数据的。如果您不想看了,到这里就可以了,基本满足所有的效果了。 然后由于最近领导给我一些任务就是比较两个字符串的相似度,通过这个启发就想通过xy向量计算字符字形的相似度。得出以下代码,首先针对”下”字进行数据测试 1. **归一化**:将所有点归一化到相同的尺度。(如果不归一,DTW有要求长度一样,会报错) **归一化点集**(Normalization of points)是指将原始点集中的每个点的坐标变换到一个特定的标准范围,以消除由于坐标范围不同而引起的差异,从而使得数据的比较更加公正和一致。具体而言,在这段代码中,归一化的目标是将每个点的坐标缩放到 `[0, 1]` 的范围内。 **为什么要进行归一化?** 在计算点集之间的相似度时(如使用动态时间规整 DTW),不同的点集可能有不同的坐标范围或单位。如果不进行归一化,可能会因为坐标差异较大,导致计算出的相似度偏差较大。归一化的过程能够消除这种影响,让两个点集具有相同的尺度,从而公平地比较它们之间的相似性。 **举个例子:** 假设有一个点集: ```python points = [(10, 20), (30, 40), (50, 60), (70, 80)] ``` 经过归一化处理后: - 最小值:`min_x = 10`, `min_y = 20` - 最大值:`max_x = 70`, `max_y = 80` 每个点将会变成: - `(10, 20)` 变成 `(0, 0)` - `(30, 40)` 变成 `(0.333, 0.333)` - `(50, 60)` 变成 `(0.666, 0.666)` - `(70, 80)` 变成 `(1, 1)` 最终,这些点就会被归一化到 `[0, 1]` 的范围内,这样它们的尺度是一致的,适合用于后续的相似度计算。归一化的目的是消除不同点集之间的坐标尺度差异,使得不同的点集可以在相同的尺度下进行比较。通过这种方式,我们可以更加公平地计算它们之间的相似度,而不会因为坐标的差异导致错误的比较结果。 2. **使用DTW进行点对齐**:保持原有的DTW对齐方法。 这里计算两个点集的相似度分数,通过DTW距离计算得出一个0~1的相似度分数。1完全相似,0完全不一样。 函数使用 `fastdtw` 函数计算归一化后的两个点集之间的 **DTW 距离**。DTW 是一种衡量两组时间序列相似度的算法,常用于处理不等长、速度不同的序列数据。在这里,它也可以用于比较两个二维点集的相似度。 3. **计算相似度**:基于对齐后的点集计算相似度。 ```python import numpy as np from fastdtw import fastdtw from scipy.spatial.distance import euclidean # 假设我们已经有了两个字形的数据 ttglyph_superstar = [ (515, 695), (515, 517), (526, 530), (749, 421), (884, 320), (838, 259), (731, 347), (515, 461), (515, -72), (445, -72), (445, 695), (59, 695), (59, 762), (942, 762), (942, 695) ] ttglyph_sourcehan = [ (515, 695), (515, 517), (526, 530), (618, 485), (720, 426), (825, 364), (884, 320), (838, 259), (788, 300), (694, 359), (606, 413), (515, 461), (515, -72), (445, -72), (445, 695), (59, 695), (59, 762), (942, 762), (942, 695) ] # 转换为numpy数组 points1 = np.array(ttglyph_superstar) points2 = np.array(ttglyph_sourcehan) def normalize_points(points): """ 归一化点集 """ if len(points) == 0: # 检查点集是否为空 return [] points = np.array(points) # 将点集转换为NumPy数组 min_x, min_y = np.min(points, axis=0) max_x, max_y = np.max(points, axis=0) # 防止除以零 if max_x == min_x: max_x = min_x + 1 if max_y == min_y: max_y = min_y + 1 normalized_points = (points - [min_x, min_y]) / [max_x - min_x, max_y - min_y] return normalized_points def calculate_similarity(points1, points2): """ 使用DTW计算两个点集之间的相似度 """ points1_normalized = normalize_points(points1) points2_normalized = normalize_points(points2) if len(points1_normalized) == 0 or len(points2_normalized) == 0: return 0.0 # 如果任一点集为空,相似度为0 #distance 是 DTW 算法计算出来的总距离,表示两个点集的整体差异。 #path 是 DTW 算法找到的最佳对齐路径,指示了如何从 points1 映射到 points2。 distance, path = fastdtw(points1_normalized, points2_normalized, dist=euclidean) # DTW 算法会计算出一组“对齐”路径,通过这个路径可以重新排列两个点集,使它们更好地对齐。根据 path 的内容,分别从 points1_normalized 和 points2_normalized 中提取对齐后的点集。 aligned_points1 = [points1_normalized[i] for i, _ in path] aligned_points2 = [points2_normalized[j] for _, j in path] # 计算对齐点之间的欧几里得距离,在最佳对齐下,每对点之间的差异。np.linalg.norm 计算的是两点之间的欧几里得距离 distances = [np.linalg.norm(np.array(p1) - np.array(p2)) for p1, p2 in zip(aligned_points1, aligned_points2)] # 算出所有欧氏距离去平局书,得出平均欧氏距距离 average_distance = np.mean(distances) similarity_score = 1 / (1 + average_distance) return similarity_score print(f"Similarity score: {calculate_similarity(points2,points1)}") ``` 得出结果 ```shell Similarity score: 0.975700703557036 ``` 发现相似度还是很高的,这里是需要忽略字体的风格的,和笔画的这些。 好的,可以通过这种相似度算法去核对超星字体对应的元数据了。 ```python import xml.etree.ElementTree as ET import json import numpy as np from fastdtw import fastdtw from scipy.spatial.distance import euclidean from tqdm import tqdm def parse_glyphs(file_path): """ 解析字体文件中的 TTGlyph 信息 """ tree = ET.parse(file_path) root = tree.getroot() glyphs = {} for glyph in root.findall(".//TTGlyph"): name = glyph.get("name") points = [] for pt in glyph.findall(".//pt"): x = int(pt.get("x")) y = int(pt.get("y")) on = int(pt.get("on", 0)) # 默认值为0,如果不存在则设为0 points.append((x, y)) # 将点集转换为字符串,作为字典的键 key = str(points) glyphs[key] = name return glyphs def get_unicode_character(name): """ 根据 glyph 名称(如 uni5148)获取对应汉字 """ if name.startswith("uni"): try: unicode_value = int(name[3:], 16) return chr(unicode_value) except ValueError: return None return None def normalize_points(points): """ 归一化点集 """ if not points: # 检查点集是否为空 return [] points = np.array(points) # 将点集转换为NumPy数组 min_x, min_y = np.min(points, axis=0) max_x, max_y = np.max(points, axis=0) # 防止除以零 if max_x == min_x: max_x = min_x + 1 if max_y == min_y: max_y = min_y + 1 normalized_points = (points - [min_x, min_y]) / [max_x - min_x, max_y - min_y] return normalized_points def calculate_similarity(points1, points2): """ 使用DTW计算两个点集之间的相似度 """ points1_normalized = normalize_points(points1) points2_normalized = normalize_points(points2) if len(points1_normalized) == 0 or len(points2_normalized) == 0: return 0.0 # 如果任一点集为空,相似度为0 distance, path = fastdtw(points1_normalized, points2_normalized, dist=euclidean) aligned_points1 = [points1_normalized[i] for i, _ in path] aligned_points2 = [points2_normalized[j] for _, j in path] distances = [np.linalg.norm(np.array(p1) - np.array(p2)) for p1, p2 in zip(aligned_points1, aligned_points2)] average_distance = np.mean(distances) similarity_score = 1 / (1 + average_distance) return similarity_score def build_mapping(xml_old_path, xml_cx_path): """ 建立思源黑体和超星字体的对照关系 """ old_glyphs = parse_glyphs(xml_old_path) print(f'思源字体:{len(old_glyphs)}') cx_glyphs = parse_glyphs(xml_cx_path) print(f'超星字体:{len(cx_glyphs)}') mapping = [] total_combinations = len(old_glyphs) * len(cx_glyphs) with tqdm(total=total_combinations, desc="Processing") as pbar: for old_key, old_name in old_glyphs.items(): for cx_key, cx_name in cx_glyphs.items(): similarity = calculate_similarity(eval(old_key), eval(cx_key)) if similarity >= 0.9: mapping.append({ "chaoxing": { "cx_name": cx_name, "cx_character": get_unicode_character(cx_name) }, "si_yuan": { "sy_name": old_name, "sy_character": get_unicode_character(old_name) }, "similarity": similarity }) pbar.update(1) return mapping if __name__ == "__main__": xml_old_path = r"D:\UserData\Desktop\思源黑体.xml" xml_cx_path = r"D:\UserData\Desktop\chaoxing_font.xml" result = build_mapping(xml_old_path, xml_cx_path) # 输出到文件 with open("glyph_mapping2.json", "w", encoding="utf-8") as f: json.dump(result, f, ensure_ascii=False, indent=4) # print(json.dumps(result[:5], ensure_ascii=False, indent=4)) ``` 但是运行效果不如人意  这么长的时间肯定是不能忍的,所有采用多线程的处理方式,cpu就应该忙起来了。 ```python from concurrent.futures import ProcessPoolExecutor, as_completed import json import numpy as np from fastdtw import fastdtw from scipy.spatial.distance import euclidean from tqdm import tqdm import xml.etree.ElementTree as ET # 其他函数不变,保持之前的代码 def calculate_similarity(points1, points2): """ 使用DTW计算两个点集之间的相似度 """ points1_normalized = normalize_points(points1) points2_normalized = normalize_points(points2) if len(points1_normalized) == 0 or len(points2_normalized) == 0: return 0.0 # 如果任一点集为空,相似度为0 distance, path = fastdtw(points1_normalized, points2_normalized, dist=euclidean) aligned_points1 = [points1_normalized[i] for i, _ in path] aligned_points2 = [points2_normalized[j] for _, j in path] distances = [np.linalg.norm(np.array(p1) - np.array(p2)) for p1, p2 in zip(aligned_points1, aligned_points2)] average_distance = np.mean(distances) similarity_score = 1 / (1 + average_distance) return similarity_score def normalize_points(points): """ 归一化点集 """ if not points: # 检查点集是否为空 return [] points = np.array(points) # 将点集转换为NumPy数组 min_x, min_y = np.min(points, axis=0) max_x, max_y = np.max(points, axis=0) # 防止除以零 if max_x == min_x: max_x = min_x + 1 if max_y == min_y: max_y = min_y + 1 normalized_points = (points - [min_x, min_y]) / [max_x - min_x, max_y - min_y] return normalized_points def parallel_calculate_similarity(old_key, old_name, cx_glyphs): """ 并行计算相似度 """ results = [] for cx_key, cx_name in cx_glyphs.items(): similarity = calculate_similarity(eval(old_key), eval(cx_key)) if similarity >= 0.9: results.append({ "chaoxing": { "cx_name": cx_name, "cx_character": get_unicode_character(cx_name) }, "si_yuan": { "sy_name": old_name, "sy_character": get_unicode_character(old_name) }, "similarity": similarity }) return results def get_unicode_character(name): """ 根据 glyph 名称(如 uni5148)获取对应汉字 """ if name.startswith("uni"): try: unicode_value = int(name[3:], 16) return chr(unicode_value) except ValueError: return None return None def parse_glyphs(file_path): """ 解析字体文件中的 TTGlyph 信息 """ tree = ET.parse(file_path) root = tree.getroot() glyphs = {} for glyph in root.findall(".//TTGlyph"): name = glyph.get("name") points = [] for pt in glyph.findall(".//pt"): x = int(pt.get("x")) y = int(pt.get("y")) on = int(pt.get("on", 0)) # 默认值为0,如果不存在则设为0 points.append((x, y)) # 将点集转换为字符串,作为字典的键 key = str(points) glyphs[key] = name return glyphs def build_mapping_parallel(xml_old_path, xml_cx_path): """ 并行建立思源黑体和超星字体的对照关系 """ old_glyphs = parse_glyphs(xml_old_path) print(f'思源字体:{len(old_glyphs)}') cx_glyphs = parse_glyphs(xml_cx_path) print(f'超星字体:{len(cx_glyphs)}') mapping = [] # 使用进程池进行并行处理 with ProcessPoolExecutor() as executor: futures = [] # 为每个思源字体字形提交任务 for old_key, old_name in old_glyphs.items(): futures.append(executor.submit(parallel_calculate_similarity, old_key, old_name, cx_glyphs)) # 通过 as_completed 获取计算结果 for future in tqdm(as_completed(futures), total=len(futures), desc="Processing"): mapping.extend(future.result()) return mapping if __name__ == "__main__": xml_old_path = r"D:\UserData\Desktop\思源黑体.xml" xml_cx_path = r"D:\UserData\Desktop\chaoxing_font.xml" result = build_mapping_parallel(xml_old_path, xml_cx_path) # 输出到文件 with open("glyph_mapping_parallel.json", "w", encoding="utf-8") as f: json.dump(result, f, ensure_ascii=False, indent=4) # 打印部分结果 print(json.dumps(result[:5], ensure_ascii=False, indent=4)) ``` 这样处理时间来到了半小时(不过cpu要满了),因为我要求把大于0.9的数据全弄出来了,所以会有很多重复的字形数据。这里还需要取出相似度最高的那一个字形数据。 ```python import json # 读取保存的结果文件并生成包含所有相似度最高数据的 high.json 文件 def find_most_similar_for_all(result_file="glyph_mapping_parallel.json", output_file="high.json"): # 读取 JSON 数据 with open(result_file, "r", encoding="utf-8") as f: data = json.load(f) # 用于存储每个 chaoxing 对应的最相似的 si_yuan 对照项 highest_similarity_entries = {} # 遍历所有条目,找出每个 chaoxing 字符对应的最相似的 si_yuan 对照项 for entry in data: cx_name = entry["chaoxing"]["cx_name"] similarity = entry["similarity"] # 如果该 cx_name 没有出现过,或者当前相似度更高,更新最相似的条目 if cx_name not in highest_similarity_entries or similarity > highest_similarity_entries[cx_name]["similarity"]: highest_similarity_entries[cx_name] = entry # print(len(highest_similarity_entries)) # 将结果保存到 high.json 文件 with open(output_file, "w", encoding="utf-8") as f: json.dump(list(highest_similarity_entries.values()), f, ensure_ascii=False, indent=4) print(f"已将结果保存到 {output_file}") # 调用函数,生成 high.json 文件 find_most_similar_for_all() ``` 至此,我们以及彻底完成了映射表的制作。然后拿数据跑一下进行测试 ```python import json # 读取 high.json 文件并加载数据 def load_high_json(file_path="high.json"): with open(file_path, "r", encoding="utf-8") as f: return json.load(f) # 根据 high.json 匹配字符串中的每个字符,返回结果字符串 def match_string_with_high_json(code, high_json_data): result = [] for char in code: # 遍历 high.json 中的所有项,查找匹配的 cx_character matched = False for entry in high_json_data: if entry["chaoxing"]["cx_character"] == char: # 根据需要将匹配的结果拼接成字符串 result.append(entry["si_yuan"]["sy_character"]) # 使用 si_yuan 对应的字符 matched = True break if not matched: # 如果没有找到匹配的项,保留原字符 result.append(char) # 将匹配结果列表合并成一个字符串 return ''.join(result) # 示例字符串 code = '下埂关于“好好埃生”的埄埆哪埇不埁准埅?' # 加载 high.json 数据 high_json_data = load_high_json() # 匹配字符串 result_string = match_string_with_high_json(code, high_json_data) print(f'超星字体:{code}') print(f'思源字体:{result_string}') ``` 得出结果 ```shell 超星字体:下埂关于“好好埃生”的埄埆哪埇不埁准埅? 思源字体:下⾯关于“好好先生”的描述哪项不太准确? ``` 好的,已经可以了,这里关于超星字体的时候,有个疑问就是为什么每个页面加载页面的字体,不能拿到全部的,我这个不知道咋弄,很困扰我,希望有大佬可以帮忙解释一下。 至此,文章彻底结束。 参考文章: 关于超星学习通网页版字体加密分析 :https://www.52pojie.cn/thread-1631357-4-1.html 从学习通复制文字乱码看前端版权保护:https://5ime.cn/xxt_font.html 最后修改:2024 年 11 月 30 日 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 如果觉得我的文章对你有用,请随意赞赏
