- explain语句提供有关mysql如何执行语句的信息,可以处理select、delete、insert、replact和update语句。
- explain执行select语句中使用的每个表返回一行信息,是按照mysql在处理语句时读取他们顺序列输出中的表。
- 对应select语句,explain会生成扩展信息,这些信息可以在explain之后通过“show warnings”查看。
二 . explain返回参数详解:
1. id : 列数字
越大越先执行,如果说数字一样大,那么就从上往下依次执行,id列为null的就表是这是一个结果集,不需要使用它来进行查询。
2. select_type列,常见的有:
1)simple:表示不需要union操作或者不包含子查询的简单select查询。有连接查询时,外层的查询为simple,且只有一个
2)primary:一个需要union操作或含有子查询的select,位于最外层的单位查询的select_type即为primary。且只有一个
3)union:union连接的两个select查询,第一个查询是dervied派生表,除了第一个表外,第二个以后的表select_type都是union
4)dependent union:与union一样,出现在union 或union all语句中,但是这个查询要受到外部查询的影响
5)union result:包含union的结果集,在union和union all语句中,因为它不需要参与查询,所以id字段为null
6)subquery:除了from句中包含的子查询外,其他地方出现的子查询都可能是subquery
7)dependent subquery:与dependent union类似,表示这个subquery的查询要受到外部表查询的影响
8)derived:from字句中出现的子查询,也叫做派生表,其他数据库中可能叫做内联视图或嵌套select
3. table : 表名
显示的查询表名,如果查询使用了别名,那么这里显示的是别名,如果不涉及对数据表的操作,那么这显示为null,如果显示为尖括号括起来的就表示这个是临时表,后边的N就是执行计划中的id,表示结果来自于这个查询产生。如果是尖括号括起来的
4 . type : 访问类型
依次从好到差:system,const,eq_ref,ref,fulltext,ref_or_null,unique_subquery,index_subquery,range,index_merge,index,ALL,除了all之外,其他的type都可以使用到索引,除了index_merge之外,其他的type只可以用到一个索引
1) system: 表中只有一行数据或者是空表,且只能用于myisam和memory表。如果是Innodb引擎表,type列在这个情况通常都是all或者index
2) const: 使用唯一索引或者主键,返回记录一定是1行记录的等值where条件时,通常type是const。其他数据库也叫做唯一索引扫描
3) eq_ref: 出现在要连接过个表的查询计划中,驱动表只返回一行数据,且这行数据是第二个表的主键或者唯一索引,且必须为not null,唯一索引和主键是多列时,只有所有的列都用作比较时才会出现eq_ref
4) ref: 不像eq_ref那样要求连接顺序,也没有主键和唯一索引的要求,只要使用相等条件检索时就可能出现,常见与辅助索引的等值查找。或者多列主键、唯一索引中,使用第一个列之外的列作为等值查找也会出现,总之,返回数据不唯一的等值查找就可能出现。
5) fulltext: 全文索引检索,要注意,全文索引的优先级很高,若全文索引和普通索引同时存在时,mysql不管代价,优先选择使用全文索引
6) ref_or_null: 与ref方法类似,只是增加了null值的比较。实际用的不多。
7) unique_subquery: 用于where中的in形式子查询,子查询返回不重复值唯一值
8) index_subquery: 用于in形式子查询使用到了辅助索引或者in常数列表,子查询可能返回重复值,可以使用索引将子查询去重。
9) range: 索引范围扫描,常见于使用>,<,is null,between ,in ,like等运算符的查询中。
10) index_merge: 表示查询使用了两个以上的索引,最后取交集或者并集,常见and ,or的条件使用了不同的索引,官方排序这个在ref_or_null之后,但是实际上由于要读取所个索引,性能可能大部分时间都不如range
11) index: 索引全表扫描,把索引从头到尾扫一遍。出现index是sql使用了索引但是没用通过索引进行过滤,一般是使用了覆盖索引或者是利用索引进行了排序分组。
12) all : 这个就是全表扫描数据文件,然后再在server层进行过滤返回符合要求的记录。(这一般比较糟糕,应该尽量避免)
5 . possible_keys:
查询可能使用到的索引都会在这里列出来,但不一 定被查询实际使用。
6 . key :
查询真正使用到的索引,select_type为index_merge时,这里可能出现两个以上的索引,其他的select_type这里只会出现一个。如果为NULL,则没有使用索引。
7 . key_len :
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。 key_len 字段能够帮你检查是否充分的 利用上了索引。ken_len 越长,说明索引使用的越充分。
8 . ref :
如果是使用的常数等值查询,这里会显示const,如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段,如果是条件使用了表达式或者函数,或者条件列发生了内部隐式转换,这里可能显示为func
9 . rows :
这里是执行计划中估算的扫描行数,不是精确值
10 . extra :
重点关注:using filesort和using temporary
1) distinct: 在select部分使用了distinc关键字
2) no tables used: 不带from字句的查询或者From dual查询
3) using filesort: 排序时无法使用到索引时,就会出现这个。常见于order by和group by语句中。(看到这个的时候,查询就需要优化了)
4) using index: 查询时不需要回表查询,直接通过索引就可以获取查询的数据。
5) using join buffer(block nested loop),using join buffer(batched key accss): 5.6.x之后的版本优化关联查询的BNL,BKA特性。主要是减少内表的循环数量以及比较顺序地扫描查询。
6) using sort_union,using_union,using intersect,using sort_intersection:
A: using intersect:表示使用and的各个索引的条件时,该信息表示是从处理结果获取交集
B: using union:表示使用or连接各个使用索引的条件时,该信息表示从处理结果获取并集
C: using sort_union和using sort_intersection:与前面两个对应的类似,只是他们是出现在用and和or查询信息量大时,先查询主键,然后进行排序合并后,才能读取记录并返回。
7) using temporary: 表示使用了临时表存储中间结果。临时表可以是内存临时表和磁盘临时表,执行计划中看不出来,需要查看status变量,used_tmp_table,used_tmp_disk_table才能看出来。这通常发生在对不同的列集进行ORDER BY上,而不是GROUP BY上。(看到这个的时候,查询需要优化了)
8) using where: 表示存储引擎返回的记录并不是所有的都满足查询条件,需要在server层进行过滤。查询条件中分为限制条件和检查条件,5.6之前,存储引擎只能根据限制条件扫描数据并返回,然后server层根据检查条件进行过滤再返回真正符合查询的数据。5.6.x之后支持ICP特性,可以把检查条件也下推到存储引擎层,不符合检查条件和限制条件的数据,直接不读取,这样就大大减少了存储引擎扫描的记录数量。extra列显示using index condition
9) firstmatch(tb_name): 5.6.x开始引入的优化子查询的新特性之一,常见于where字句含有in()类型的子查询。如果内表的数据量比较大,就可能出现这个
10) loosescan(m…n): 5.6.x之后引入的优化子查询的新特性之一,在in()类型的子查询中,子查询返回的可能有重复记录时,就可能出现这个
11)no exists : MYSQL优化了LEFT JOIN,一旦它找到了匹配LEFT JOIN标准的行,就不再搜索了
]]>语法是这样的
SELECT CONCAT_WS(' ',snh.userneeds, snh.beizhu) AS connect_info ,snh.createTime, lmu.createTime as regTime
FROM `supplier_needs_history` as snh
LEFT JOIN member_user as mu
ON snh.userId = mu.id
LEFT JOIN login_member_user as lmu
on mu.companyCode = lmu.companyCode
WHERE mu.companyName ='诚润建工集团有限公司'
ORDER BY snh.createTime DESC
LIMIT 3;一开始用的是CONCA函数,但是当时出现了以下的情况

也就是说,当我连接的两个字段里面其中一个为null的时候,拼接后的结果也是null
在查询之后使用了CONCAT_WS函数
这是结果
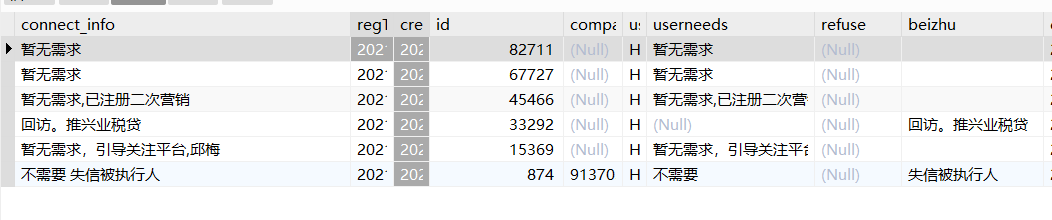
CONCAT():CONCAT()函数用于拼接两个或多个字符串。SELECT CONCAT(first_name, ' ', last_name) AS full_name FROM employees;CONCAT_WS():CONCAT_WS()函数用于拼接字符串,并在每个字符串之间插入指定的分隔符。SELECT CONCAT_WS(', ', last_name, first_name) AS full_name FROM employees;CONCAT_NULL_YIELDS_NULL: 这是 MySQL 的系统变量,用于控制拼接操作的行为。如果设置为ON(默认值),当任何一个操作数为NULL时,拼接结果将为NULL。如果设置为OFF,则不会将NULL视为NULL。字符串运算符 (
||): MySQL 支持标准 SQL 中的字符串拼接运算符||。SELECT first_name || ' ' || last_name AS full_name FROM employees;
这些函数和运算符允许您在 SQL 查询中执行字符串拼接操作。您可以根据自己的需求选择适当的函数或运算符。
]]>在 MySQL 中,当使用 LIKE 条件进行字符串匹配时,如果在索引列上使用 LIKE %索引% 和 LIKE 索引% 这两种形式,会有不同的查询性能和结果。
LIKE %索引%:
这种情况下,%通配符位于搜索字符串的开头和结尾,表示可以匹配任意字符。例如,假设索引列是column_name,我们执行以下查询:SELECT * FROM table_name WHERE column_name LIKE '%索引%';这将查找
column_name列中包含有索引子字符串的所有行。LIKE 索引%:
这种情况下,%通配符仅位于搜索字符串的结尾,表示只匹配以指定字符串开头的值。例如,假设索引列仍然是column_name,我们执行以下查询:SELECT * FROM table_name WHERE column_name LIKE '索引%';这将查找
column_name列中以索引开头的所有行。
区别:
LIKE %索引%的查询可能会涉及全表扫描,因为通配符%出现在搜索字符串的开头和结尾,导致无法利用索引。LIKE 索引%的查询可以利用索引,因为通配符%仅出现在搜索字符串的结尾,允许数据库引擎使用索引的前缀部分进行匹配,从而提高查询性能。
通常情况下,如果可能,应尽量避免使用 LIKE %索引% 这种形式,特别是对于大型数据表,因为它可能导致较慢的查询性能。如果只需要查找以某个字符串开头的值,应该使用 LIKE 索引% 形式,以便利用索引优化查询。
因为windows有任务计划程序的原因,所以我们只需要写好bash脚本就可以。
bash
:: 配置数据库用户
SET DB_USER=root
:: 配置数据库密码
SET DB_PASSWORD=root123
:: 配置备份的数据库名称
SET DB_NAME=security_enterprise
:: 配置备份的文件路径
SET SAVE_PATH=D:\MySqlBackup
:: 配置mysqldump的路径,有空格的要加上双引号
SET MYSQL_DUMP_PATH=D:\Environment\mysql-5.7.40\bin\mysqldump.exe
:: 开始工作
:: 跳转到工作目录下
%SAVE_PATH:~0,2%
cd %SAVE_PATH%
:: 设置变量:备份文件名
SET BAK_FILE=%SAVE_PATH%\security_enterprise_bak_%date:~0,4%_%date:~5,2%_%date:~8,2%.sql
:: 开始做备份
%MYSQL_DUMP_PATH% -u%DB_USER% -p%DB_PASSWORD% %DB_NAME%>%BAK_FILE%在里面很清楚了,在此不做赘述。
windows任务计划程序
设置名称描述以及安全选项
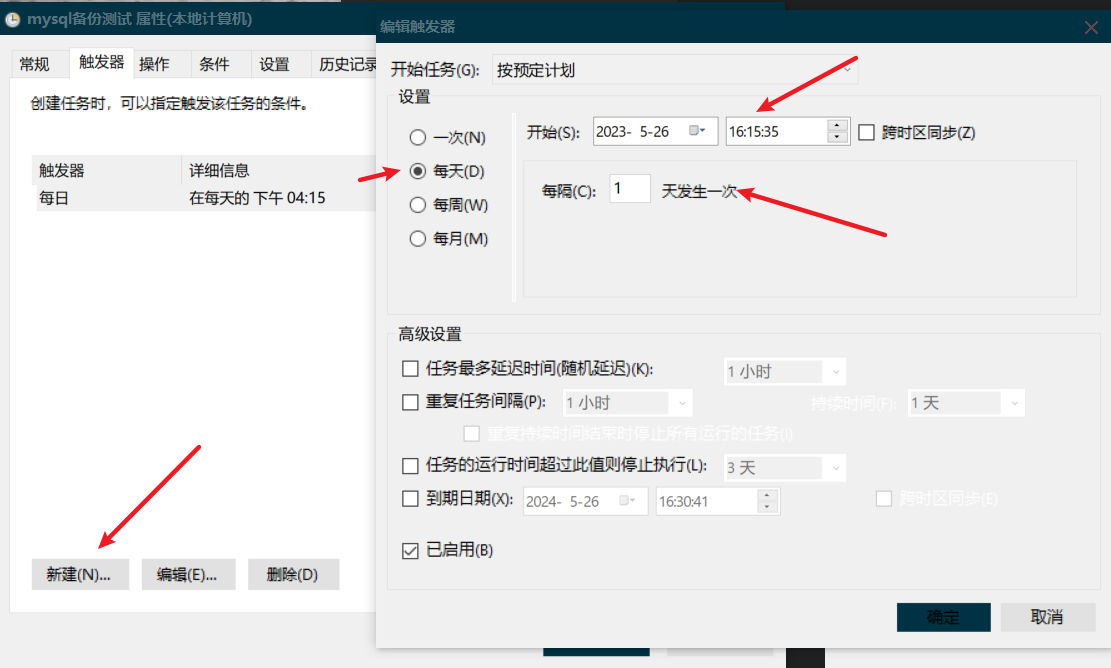
设置触发器
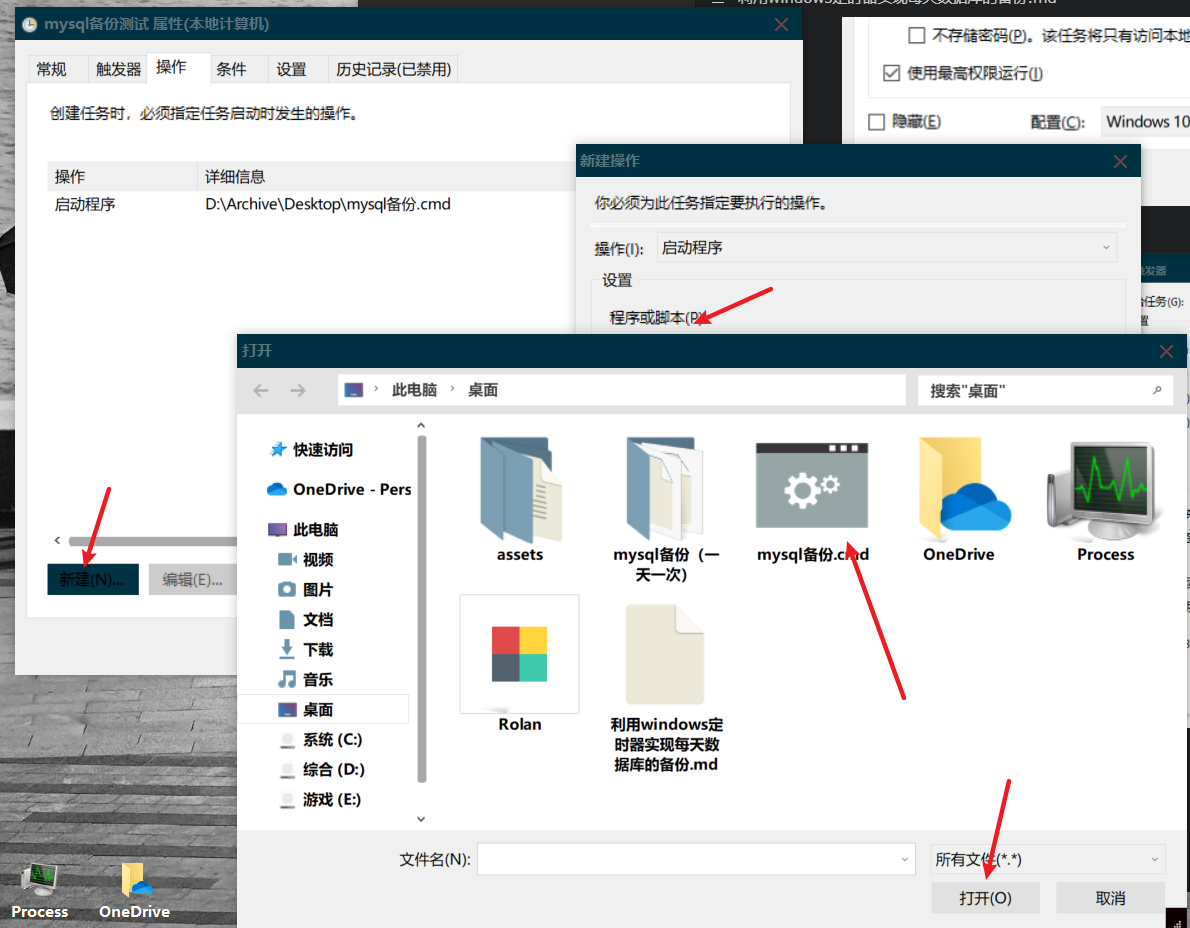
设置操作
设置一下意外情况
这里是防止备份失败进行的容错处理,可以做此步骤
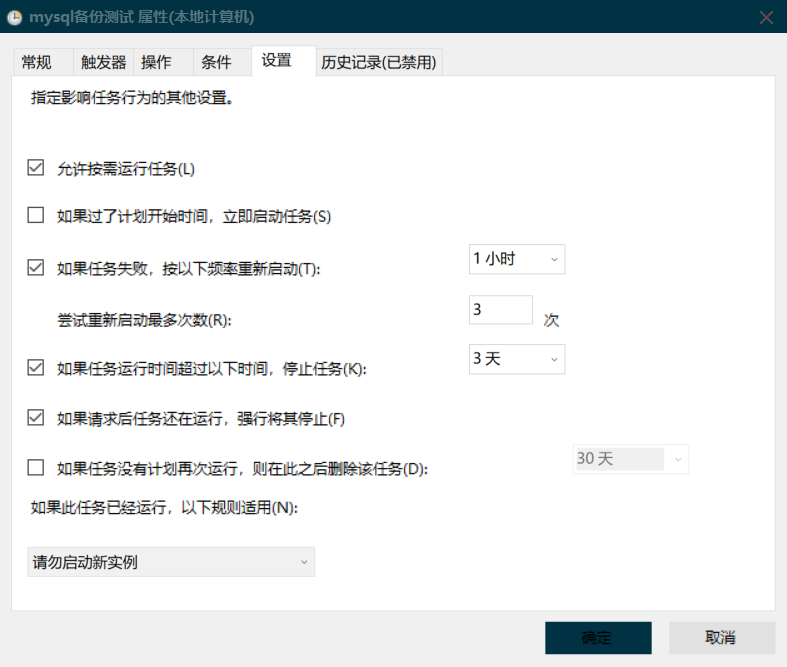
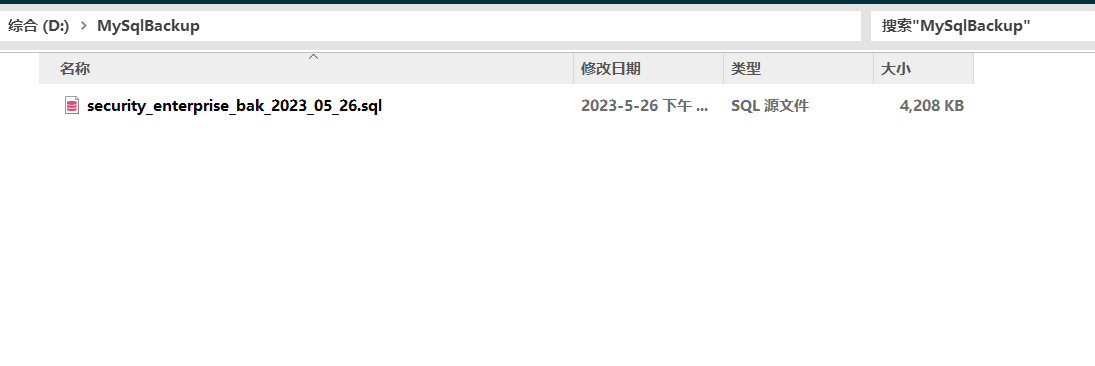
经过一系列的设置,就会每天在固定时间在我的D:\MySqlBackup目录下面生成一个备份文件,防止出错了。
Error Code: 1067 - Invalid default value for 'LOCK_TIME_'
查阅资料知道是mysql从5.7开始,默认是严格模式,严格遵从SQL92规范。
公司mysql版本:5.7.25
我的mysql版本:5.7.40
因为mysql差距不大的原因,所以猜测,应该是我没开启timestamp默认值规则
先查看是否开启了
show variables like 'explicit_defaults_for_timestamp'; 忘了截图了,不过查询出来的结果是off
设置开启
set global explicit_defaults_for_timestamp = ON;再次查看是否开启
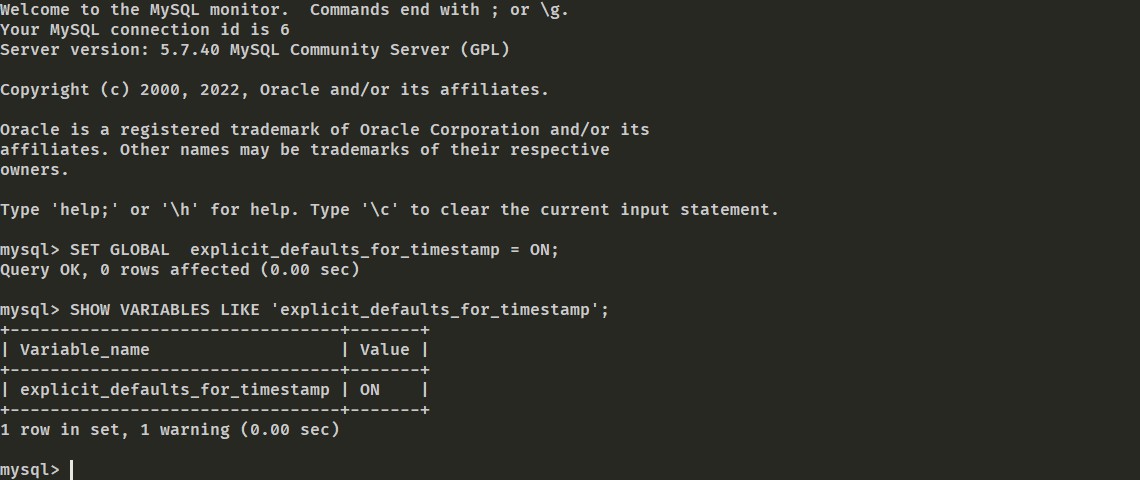
开启了,然后再次导入数据库。就可以了。
还有一种解决方式是去除掉关于时间这些not null字段,也可以,不过实在是太多了,所以就没有选择此种方法。
参考连接:
]]>`mysql这么关键的东西竟然没安装,实在是蠢。网上找了半天没有msi的安装器,只能google学习用压缩包方式安装了。。。特此学习记录下载
下载地址(选择该地址可以下载历史版本)
https://downloads.mysql.com/archives/community/
安装
解压到路径

在解压目录下创建my.ini
[client]
# 设置mysql客户端默认字符集
default-character-set=utf8
[mysqld]
# 设置3306端口
port=3306
character_set_server=utf8
# 解压目录
basedir=D:\Environment\mysql-5.7.40
# 解压目录下data目录,这里血药自己创建data
datadir=D:\Environment\mysql-5.7.40\data
default-storage-engine=INNODB
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
[WinMySQLAdmin]
D:\Environment\mysql-5.7.40\bin\mysqld.exe设置MYSQL的环境变量
- 新增系统变量
MYSQL_HOME路径写D:\Environment\mysql-5.7.40 - 在系统变量Path后面追加
;%MYSQL_HOME%\bin
安装MYSQL
在解压目录的\bin下(D:\Environment\mysql-5.7.40\bin),开启命令窗口,这里我用的是cmder
执行命令初始化数据库
mysqld -install
mysqld --initialize --console
mysqld --initialize --console命令,可以得到mysql的初始密码,用mysqld --initialize 的目的是初始化data目录。红框之内的是我的密码的位置。
接着就是在输入net start mysql启动服务(这里需要管理员权限)
开始使用`mysql,输入命令:mysql -uroot -p,然后输入刚才的初始密码
修改密码
mysql> alter user 'root'@'localhost' identified by '123456';
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
mysql> exit;
Bye- 输入命令:
mysql -uroot -p,然后尝试新密码